© 2024. All rights reserved.
© 2024. All rights reserved.
At the Network Systems Science and Advanced Computing (NSSAC) division of the Biocomplexity Institute at the University of Virginia, we have developed a pipeline for producing synthetic, or digital twin, populations that are representative of the actual populations of the world. At a high level, a digital twin population represents the people of a region along with selected demographic attributes like age and gender, groups them into households, assigns them activities over a period of time (day or week) along with locations where the activities take place, thus identifying where interactions between population members occur. Digital twin populations can be used to run modeling simulations (e.g., for epidemic forecasting, predicting social unrest, disaster planning, etc.) for areas where detailed population data is unavailable, or where usage of detailed data may raise privacy concerns.
The Synthetic Information Exploration and Visualization Engine (SIEVE) presents a web-based, high-level visualization of the digital twin populations we have developed so far. Like the populations themselves, this application is a work in progress, and more detailed visualizations will be added over time.
Our digital twin populations are collated as a collection of data sets, where each data set represents the synthetic population for a country or state, either of which will be referred to here as a region. Each synthetic population is constructed using mathematical models, collected data about the region’s demographic makeup, as well as statistically imputed data for regions missing one or more of the data sources required for the constructions. Each population has an associated metadata file providing the list of collected and imputed data sources used in its construction.
Digital twin populations are made up of five general components:
Person data contains data for each person in the populations, including demographic attributes, such as age and gender, along with a household ID.
Household data contains data at the household level, such as household income, number of workers in the household, and household language.
Residence- and activity locations data contains data about residence locations and activity locations, including what activity types are supported at these locations.
Activity location assignment data: A series of activities is assigned to each person for a period of time (either a day or a week). Based on the activity type, residence- and activity locations are assigned to indicate where each activity takes place.
Contact matrix data: a POLYMOD-type contact matrix constructed from a network representation of the location assignment data and a within-location contact model. This can be used to determine the number of people that came in contact; this kind of information can be useful, for example, in predicting the spread of diseases.
While reasonable effort has been made to make each population as representative as possible, given the collected and imputed data sources, we make no guarantee about their accuracy. This is because the population construction relies on data that is hard or impossible to collect or may only be available from commercial sources. Some data, such as activity sequence templates, can be dated. In addition, we use statistically imputed data which omits seasonal migration patterns as are present in West Africa and the Sub-Saharan regions; this limitation should be carefully considered when using this data. We are also aware of differences in industrialized countries versus developing countries regarding work locations (e.g., differences in labor-intensity for farming). These differences will be addressed in future populations as modeling and data advances are made.
Because new data sources become available over time and our processes undergo continuous revision, we may produce multiple versions of digital populations per region. In addition, because highly detailed demographic and statistical data are available for some regions (like the US), our digital twin populations for such areas can also be more comprehensive; as a result, we also classify our populations as either Coarse or Detailed. We also subject our digital twin populations to rigorous quality assurance analyses; from this, we collate quality scores for each facet of the population to evaluate their representativeness. We use these results to guide us as we improve our process.
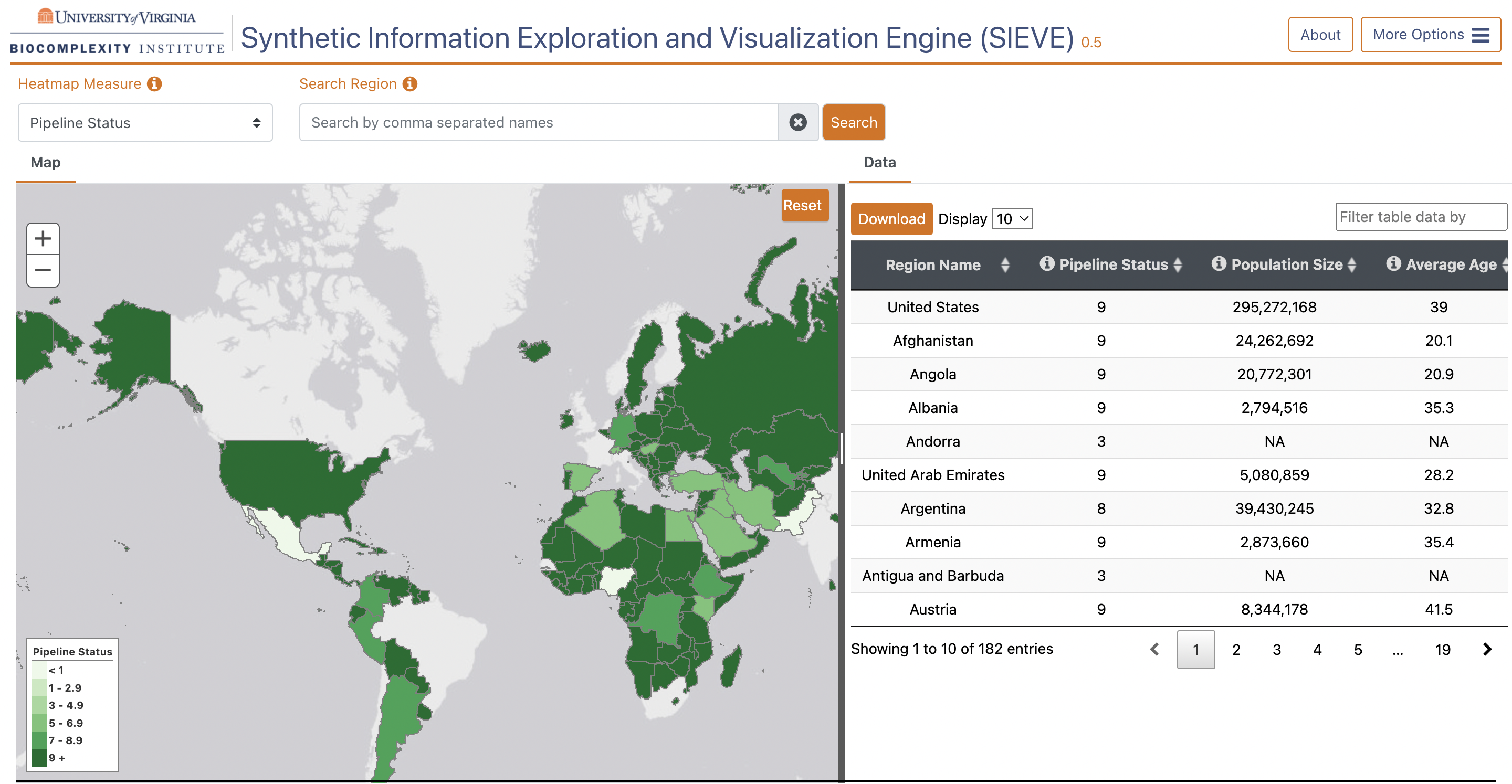
SIEVE provides a web-based methodology for visualizing our digital twin populations. This Beta release (0.5) includes the following features:
Heat Map: Users can see which countries have digital populations on the heat map, and they can also select from Heat Map Measures to indicate the criteria they would like to visualize on the map; these measures currently include Population Size, Number of Households, Average Household Size, Average Age, and more.
Click Regions for More Information: Users can click on regions to display a popup box that contains the precise values for Population Size, Number of Households, Average Household Size, and Average Age. Where available, users can also click on the Next Level link to expose subregions below the selected region on the map; most countries have at least one level of subregion (e.g., provinces or states), although many, including the United States, support two levels of subregions (e.g., states and counties.)
Data Tab: The data tab displays a subset of the region attributes, including the four measures available in the popup, the heatmap measures, and others. Users may download the data as a csv file.
Search tool: Users can search for a specific subregion depending on the layer they are on. For example, at the top (Country) level, they can search by country name; at the second (state/province) layer, they can search for states or provinces; and on the third layer, they can search for counties or other subregions.
This project was supported by the National Science Foundation under the NSF RAPID: COVID-19 Response Support: Building Synthetic Multi-scale Networks (PI: Madhav Marathe, Co-PIs: Henning Mortveit, Srinivasan Venkatramanan; Fund Number: OAC-2027541).
Copyright © 2022, UVA; ALL RIGHTS RESERVED. THE CONTENTS OF THIS DASHBOARD–INCLUDING DATA, MAPS, AND PLOTS–IS PROVIDED TO THE PUBLIC SOLELY FOR RESEARCH AND ACADEMIC PURPOSES. UVA PROVIDES NO WARRANTIES, CLAIMS OR REPRESENTATIONS–WHETHER EXPRESS, IMPLIED, OR STATUTORY–WITH RESPECT TO THIS DASHBOARD, INCLUDING, WITHOUT LIMITATION, WARRANTIES OF QUALITY, PERFORMANCE, NON–INFRINGEMENT, MERCHANTABILITY, ACCURACY, ADEQUACY, VALIDITY, RELIABILITY, COMPLETENESS, OR FITNESS FOR A PARTICULAR PURPOSE, AND DISAVOWS ANY REPRESENTATIONS OR WARRANTIES CREATED BY COURSE OF DEALING, COURSE OF PERFORMANCE, TRADE USAGE OR OTHERWISE. UNDER NO CIRCUMSTANCES WILL UVA HAVE ANY LIABILITY FOR ANY LOSS OR DAMAGE INCURRED AS A RESULT OF THE USE OF THIS DASHBOARD OR RELIANCE ON ANY INFORMATION PROVIDED HEREIN. THIS DASHBOARD MAY INCORPORATE DATA OR OTHER CONTENT BELONGING TO OR ORIGINATING FROM THIRD PARTIES. WE DO NOT WARRANT, ENDORSE, GUARANTEE, OR ASSUME RESPONSIBILITY FOR THE ACCURACY OR RELIABILITY OF ANY THIRD-PARTY INFORMATION.